La Notion des cubes
Contexte
-
Utilisation des entrepôts des données
Dan une entreprise, le flux des informations est très important notamment pour une grande structure. Cette dernière peut avoir des milliers de transactions par jour qui sont créés dans plusieurs services : Production, Commercialisation, Achat, Logistique, Bureau d’étude, GRH, Comptabilité, …
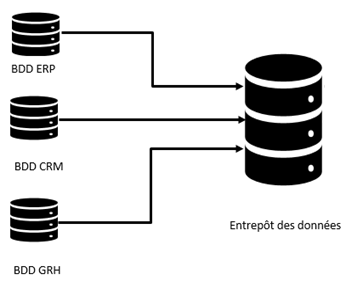
Les Bases de données permettent de stocker ces transactions en les sauvegardant l’une après l’autre dans un ordre chronologique. En fin d’exercice, nous pouvons se trouver avec des millions de lignes, dans plusieurs tables. Les données d’une grande entreprise peuvent même être stockées dans plusieurs bases de données : Base de données ERP, base de données CRM, base de données GMAO, base de données d’une application de gestion de la qualité.
Les bases de données sont gérées par des SGBDR (Systèmes de gestion de bases de données relationnelles), qui permettent d’ajouter, supprimer ou modifier un enregistrement et d’effectuer des requêtes simples. Ce sont des systèmes opérationnels conçus pour le OLTP (On-Line Transaction Processing).
Les décideurs ont besoin d’un système qui fournit une seule structure contenant toutes les données et pouvant répondre à des questions plus complexes de type : Combien nous avons vendu de l’article x dans la région y durant le mois de décembre dans le cadre d’une promotion.
La solution est d’utiliser les entrepôts de données, en anglais Datawarehouse. C’est une collection d’information provenant des différentes bases de données, où les informations sont organisées et filtrés afin d’avoir un système informationnel. Donc c’est un système transversal qui complète le système opérationnel et qui est orienté vers l’analyse de données.
2. Conception des entrepôts de données.
Les entrepôts sont dits des bases de données multidimensionnelles. Ils sont gérés par un système dit OLAP (On-Line Analytical Processing), au contraire des bases de données relationnelles, qui sont gérées par des systèmes OLTP (On-Line Transaction Processing) et qui sont des bases bidimensionnelles.
La conception d’une base de données multidimensionnelle, repose sur un schéma en étoile comme le montre la figure suivante :
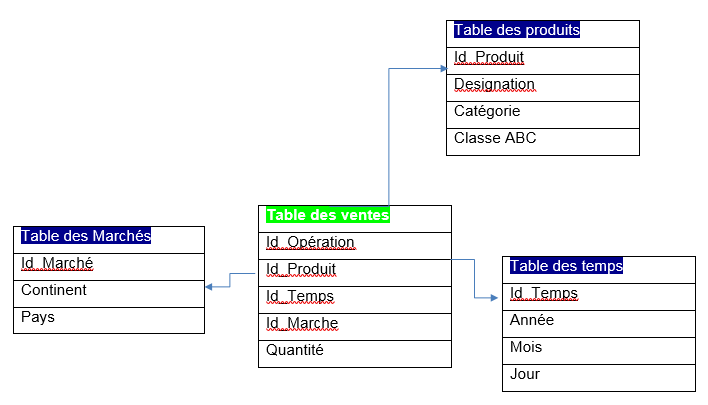
Les Tables (Marchés,Temps,Produits ) sont les dimensions. La table des ventes est la table des faits, c’est la table de mesures. Autrement dit, c’est la table où stocker les informations et les organiser de façon à avoir les ventes par marché, par produit et en fonction de temps. Les dimensions sont donc des critères.
Les tables dans un entrepôt de données sont déjà identifiés. Les tables des dimensions commencent par « Dim » alors que les tables des faits commencent par « Fact ».
3. Les cubes
Une fois les données sont organisées dans un entrepôt de données, l’utilisateur peut facilement interroger le système par des requêtes complexes. Pour des raisons d’optimisation et dans le but de minimiser le temps de calcul, nous avons introduit la notion des cubes. Il s’agit de prendre une partie de l’entrepôt de données qui concerne un seul sujet : par exemple cube de ventes, cube des achats, cube de la production, cube GRH...
Les cubes OLAP sont donc les résultats de travail sur l’entrepôt. Le schéma global du projet est ainsi :
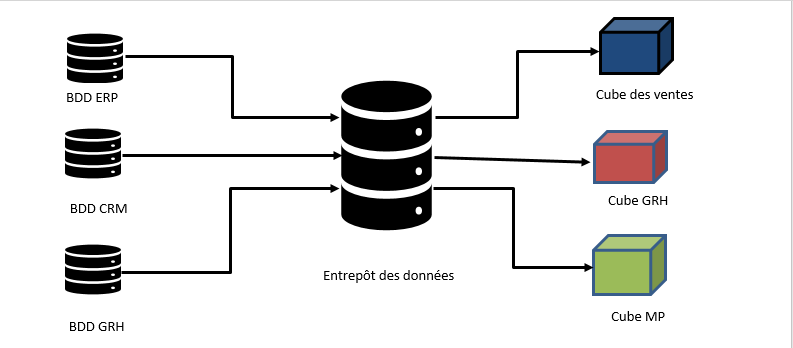
Le passage de l’entrepôt vers les cubes se fait en utilisant par exemple l’outil SQL Server Analysis Service.
Utilité d’un cube
Nous définissons les notions suivantes :
- Mesures : Ce sont les entités que nous voudrions mesurer et suivre leur évolution : Ventes, Production, consommation MP...
- Dimensions : Ce sont les axes selon lesquelles nous organisons l’information.
- Les attributs : Chaque dimension est caractérisée par une clé et un ensemble d’attributs. Ceci permet de définir la notion de la hiérarchie. Chaque attribut a son niveau d’hiérarchie dans le tableau de dimension. Cela permet d’agréger les données, par exemple supposant que nous avons une dimension Marché contenant la liste des pays, nous pouvons faire un niveau hiérarchique 1 classant les pays en gouvernorat, puis un niveau hiérarchique 2 classant les gouvernorats en départements...
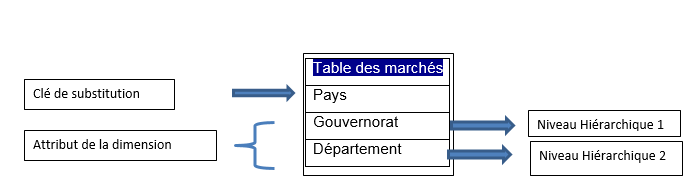
- Les fonctions d’agrégation : c’est la fonction que nous appliquerons sur l’ensemble des mesures que nous aurons à l’intersection des différentes dimensions. La fonction d’agrégation la plus courante est Sum mais nous pouvons par exemple utiliser la fonction moyenne, max min... De ce fait, nous pouvons dans un cube des ventes avoir la somme des ventes par régions, comme nous pouvons avoir la meilleure vente réalisée par région par exemple.
- KPI : indicateur de performance clé. C’est un indicateur que nous fixons la formule de calcul et que le serveur tient de le calculer sur une mesure donnée.
Donc grâce à sa structure, le Cube OLAP permet à son utilisateur d’avoir une source de données uniquement pour son métier (Cube ventes, Cube Grh,Cube Achat,..) , d’avoir les mesures organisées avec la possibilité d’utiliser les hiérarchies : par exemple, il peut avoir les ventes dans un pays , et par un simple clic avoir les ventes par gouvernorat ou encore par département. Il peut aussi avoir plusieurs fonctions d’agrégation comme la moyenne, vente maximale, …
Il y’a aussi les KPIs qui sont calculés automatiquement dans le serveur.
L’utilité d’un cube se met en valeur surtout lorsque le volume de données devient gigantesque. Par exemple les bases de données d’un opérateur téléphonique, ou une société de distribution. Pour ces exemples, le temps d’exécution en utilisant des bases de données relationnelles est très coûteux. Alors qu’en utilisant les cubes les résultats sont presque instantanés.
Afin de visualiser les données stockées dans un cube, nous pouvons utiliser Excel. Cela ressemble à un tableau croisé dynamique.